Overview
Conversational AI Memory via a Dynamic, Self-Describing Knowledge Graph
This work represents a shift from simple, stateless RAG to a sophisticated, structured and stateful AI architecture where memory is not just a retrieved document, but a evolving and self-describing model of the external knowledge and the conversation itself.
Current Implementation Status:
- KG architecture and services: Done
- Consolidation Module: Done
- Retrieval Module v1 (Hybrid Recall): Done, testing
- Retrieval Module v2 (GNN powered): Designing, literature reviewing

KG Design
The objective is to maintain a dynamic Knowledge Graph where structure and meaning are defined by node and edge attributes.
Node Design
Nodes are the core entities in our memory graph. Each node includes the following key attributes:
id: A system-generated unique identifier (e.g.,<timestamp>_<sanitized_label>).type: The node’s primary role, chosen from a predefined, hierarchical schema (e.g.,category→event_node→sub_event).label: A concise, human-readable name for the node (e.g., “Paris Conference Planning”).description: A detailed, text-based account of the node’s content (e.g., a conversation summary, knowledge details).description_embedding: A dense vector representation of thedescription, generated by a Sentence-Transformer model. This serves as the initial feature for both semantic search and the GNN input feature.status: The node’s lifecycle state, eitheractiveorarchived.update_time: A timestamp tracking the last modification.

Relation (Edge) Design
Edges define the rich, typed relationships between nodes, forming the semantic and structural backbone of the graph.
label: The human-readable meaning of the relationship (e.g.,HAS_GOAL,REFERENCES_KNOWLEDGE,PRECEDES).type: The category of the relationship:structural: Defines the graph’s organizational backbone.semantic: Represents meaningful connections between entities.
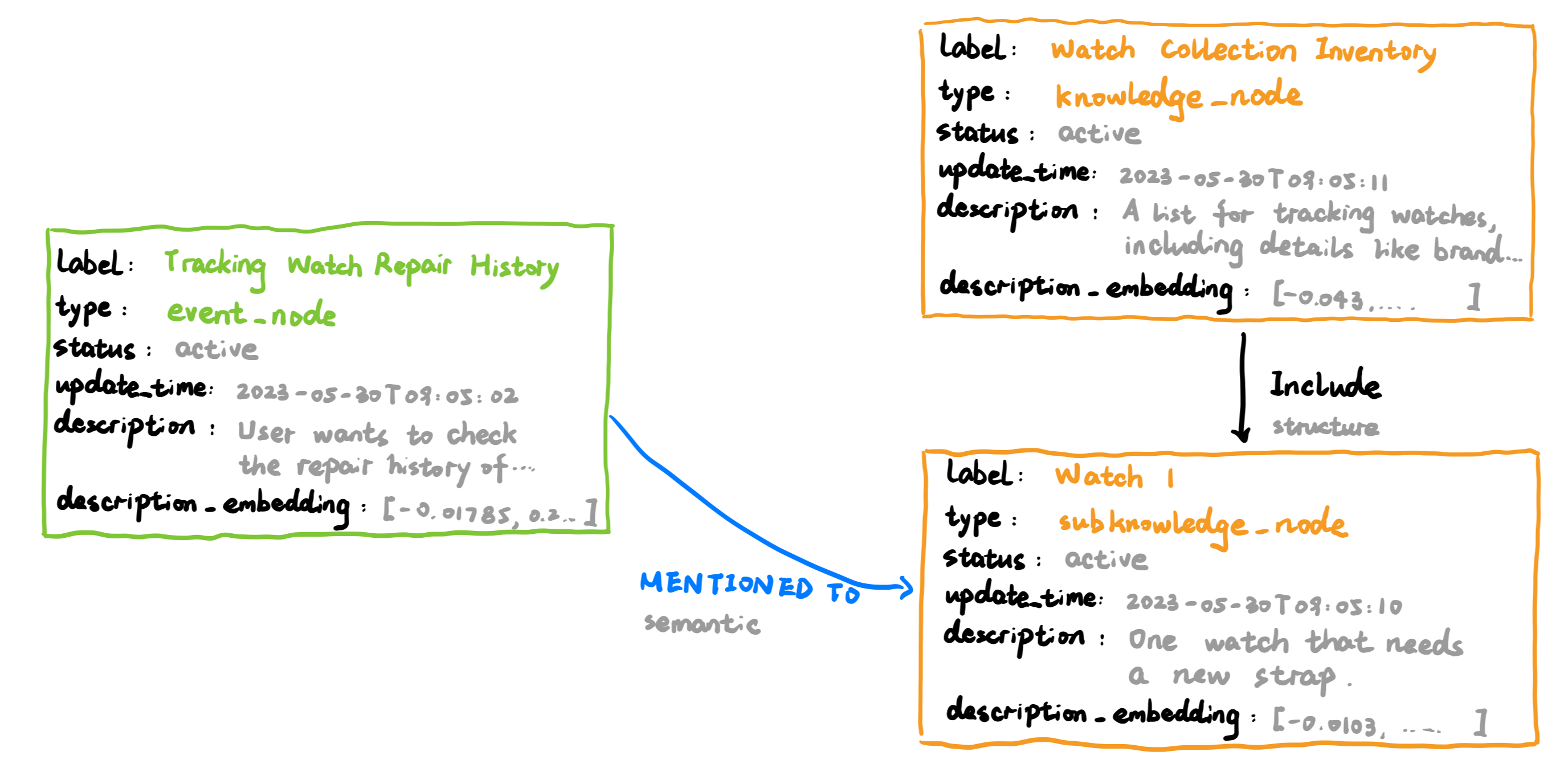
Module: Context Retrieval
The ability to retrieve relevant historical context is central to the agent’s intelligence. The project defines a two-stage evolution for this module.
V1: Hybrid Recall Engine
This initial system establishes a powerful, non-graph-aware retrieval baseline. It is used to generate the initial KG from historical data and serves as a crucial benchmark for the GNN.
- Component 1: Multi-Intent Query Generator: An LLM analyzes the user’s turn and generates one or more precise query objects.
- Component 2: Hybrid Search Powerhouse: For each query, it performs two parallel searches on all nodes:
- Keyword Search: A BM25 index on node
descriptiontexts. - Semantic Search: An ANN search using the
description_embeddingattribute.
- Keyword Search: A BM25 index on node
- Component 3: Fusion & Reranking: The results are merged using Reciprocal Rank Fusion (RRF) and optionally reranked by a lightweight model.
V2: GNN-Powered Retrieval
This advanced system leverages the graph’s relational structure to achieve superior retrieval performance.
- Core Model: A Heterogeneous Graph Transformer (HGT) trained to produce “context-aware” node embeddings.
- Input: The GNN takes the pre-computed
description_embeddingof a node and its neighbors as its initial input features. - Output: A final, structurally-informed embedding that represents the node’s role and context within the entire graph. This output embedding is stored in a dedicated vector database (e.g., Milvus) for retrieval.
- Workflow: The retrieval process is a single, highly efficient ANN search in the GNN-produced embedding space, followed by the same optional reranking step.
Module: Context-Aware Consolidation
This module is the “intelligent writer” for the KG. It is decoupled into two distinct processes: a real-time, two-stage consolidation pipeline and an asynchronous classification service.
Real-time: Two-Stage Consolidation Pipeline
This pipeline runs for every new dialogue turn to integrate information immediately.
- Stage 1: Strategy & Structure Generation (The “Architect” Model)
- Model: A powerful, reasoning-focused LLM (e.g.,
gemini-2.5-flash). - Input: The new dialogue turn and the context retrieved by the active Retrieval Module (v1 or v2).
- Task: Decides what structural changes to make to the graph (
add_node,update_node,add_relation). It generates a “blueprint” of these operations for “unclassified” event and knowledge nodes.
- Model: A powerful, reasoning-focused LLM (e.g.,
- Stage 2: Node Detail Population (The “Scribe” Model)
- Model: A lightweight, efficient model (e.g., a fine-tuned
gemma-3). - Input: The dialogue, retrieved context, and the architect’s blueprint.
- Task: Performs a focused information extraction task to populate the
labelanddescriptionfor each operation in the blueprint. When adescriptionis created or updated, thedescription_embeddingis generated/updated accordingly.
- Model: A lightweight, efficient model (e.g., a fine-tuned
Asynchronous: Node Classification Service
This is a background process that runs periodically to organize the graph.
- Task: It scans the KG for
event_nodeandknowledge_nodeentities that are “unclassified” (i.e., not yet linked to a parentevent_categoryorknowledge_categorynode). - Mechanism: It uses a dedicated, lightweight classification model (which can be a fine-tuned LLM or a traditional classifier) to determine the most appropriate category for each unclassified node.
- Action: Upon successful classification, it creates the
structuralCONTAINSrelationship from the parent category node to the child node, thus completing the graph’s hierarchical organization.
This decoupled approach makes the real-time consolidation process simpler and faster, while still ensuring the graph remains well-organized over time.
Next Step
The project follows a rigorous, two-version development plan to ensure robust evaluation and scientifically sound conclusions.
- Step 1: Run the Baseline (v1)
- Use this v1 system to process a large historical dialogue corpus, generating the “base knowledge graph” needed for GNN training.
- Step 2: Train the GNN (v2)
- On the static “base knowledge graph,” perform a large-scale, offline pre-training of the HGT model.
- Training Strategy: Employ a hybrid self-supervised learning objective, combining Link Prediction (to learn graph structure) and Contrastive Learning (to learn semantic robustness), as detailed in the research plan.
- Step 3: Deploy and Evaluate
- Deploy the v2 system with the trained, frozen GNN encoder.
- On a held-out test set of conversations/queries, conduct a thorough comparative analysis of the v1 and v2 retrieval modules.
- The primary goal is to demonstrate that the structural awareness of the v2 GNN provides a statistically significant performance improvement over the powerful v1 hybrid search baseline.