Paper PDF: Du et al. - 2025 - Rethinking Memory in AI Taxonomy, Operations, Topics, and Future Directions.pdf
Paper Bib: Du, Yiming, et al. Rethinking Memory in AI: Taxonomy, Operations, Topics, and Future Directions. arXiv:2505.00675, arXiv, 1 May 2025. arXiv.org, https://doi.org/10.48550/arXiv.2505.00675.
Scope and Purpose of the Survey
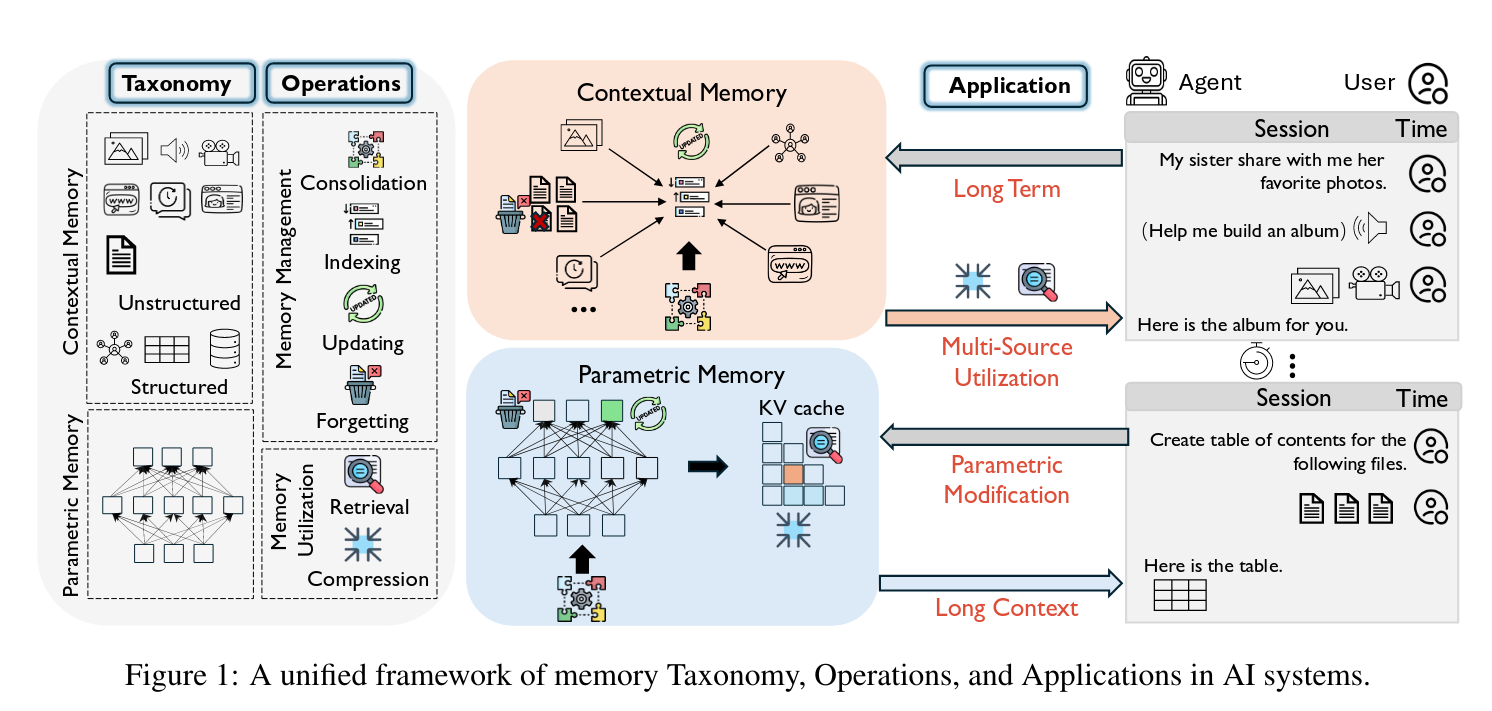
- Scope: The foundational aspects of memory in AI systems, particularly LLM based agents
- Purpose: The previous surveys have explored memory applications with LLMs, they often neglect the fundamental “atomic operations” that govern memory dynamics.
The authors argue that a unified and comprehensive view of memory operations, along with a structured categorization of benchmarks and tools, has been lacking in prior work
Key Insights from the Survey
- Primary Taxonomy: The survey categorizes memory into three types:
parametric memory,contextual-unstructured memory, andcontextual-structured memory. It further classifies these by temporal span into long-term and short-term memory Page 1: Introduction. - Fundamental Operations: Six fundamental memory operations are identified:
Consolidation,Updating,Indexing,Forgetting(collectively Memory Management), andRetrieval,Compression(collectively Memory Utilization) Page 1: Abstract. - Major Research Topics: The survey maps these operations and taxonomies to four primary research topics: Long-Term Memory, Long-Context Memory, Parametric Memory Modification, and Multi-Source Memory Page 2: Introduction.
- Trends and Challenges: The paper highlights emerging trends based on high-Relative Citation Index (RCI) papers and discusses current limitations and future directions within each research topic Page 2: From Operations to System-Level Topics. For example, in long-term memory, challenges include modeling the evolution of personalized memory and leveraging time-indexed memory for long-term reasoning Page 8: Long-term Memory.
Survey Methodology
The authors conducted a comprehensive literature analysis by collecting and reviewing over 30,000 top-tier conference papers published between 2022-2025 from NeurIPS, ICLR, ICML, ACL, EMNLP, and NAACL Page 2: Introduction. To identify influential memory-focused studies, they applied the Relative Citation Index (RCI), which ranks papers by normalized citation impact over time Page 2: Introduction. The survey also includes curated datasets, methods, and tools related to AI memory Page 1: Abstract.
Critical Analysis
It highlights limitations within the surveyed research areas, for instance, noting that long-term assistants rarely model the evolution of personalized memory or that current parametric editing methods lack mechanisms for broader memory evolution Page 8: Long-term Memory; Page 11: Parametric Memory Modification.
Relatives and Insights
This survey is highly relevant for developing a Long-Term Memory Benchmark, particularly through its structured approach to datasets and evaluation.
- Informing Benchmark Design through Identified Gaps: The survey points out that while some benchmarks for long-term memory exist, there’s a need for more nuanced evaluation. For instance, it mentions that “Time-indexed memory improves retrieval, but its use for long-term reasoning remains limited” Page 8: Long-term Memory. This insight suggests that a new benchmark could specifically target the evaluation of temporal reasoning capabilities over extended periods, going beyond simple retrieval.
- Dataset Curation and Categorization: The paper explicitly reviews and categorizes datasets relevant to long-term memory (see Table 2 Page 27: Table 2). This table provides a starting point for selecting or adapting existing datasets for a new benchmark. For example, datasets like:
- LongMemEval Reading - (Benchmark) LongMemEval is designed to “Benchmark chat assistants on long-term memory abilities, including temporal reasoning.”
- LoCoMo aims to “Evaluate long-term memory in LLMs across QA, event summarization, and multimodal dialogue tasks.”
- MemoryBank focuses on enhancing LLMs with long-term memory capabilities and adapting to user personalities and contexts.
- PerLTQA explores “personal long-term memory question answering ability.”
- Operational Focus for Task Design: The survey’s detailed breakdown of memory operations (Consolidation, Indexing, Updating, Forgetting, Retrieval, Compression) Page 3: Memory Operations can inform the design of specific tasks within the benchmark. A robust benchmark should evaluate how well systems perform each of these operations in a long-term context. For instance:
- Consolidation tasks could evaluate how new information from user interactions is integrated into the persistent KG.
- Indexing and Retrieval tasks are crucial for KG-based memory, and the benchmark could assess the efficiency and relevance of information retrieved from the KG over long histories.
- Updating tasks could test the system’s ability to modify existing KG nodes/edges based on new, potentially conflicting information, reflecting a dynamic user model.
- Forgetting tasks could evaluate the controlled removal of outdated or irrelevant information from the KG.
- Metrics and Evaluation Protocols: The survey implicitly points to the need for metrics that go beyond simple accuracy. The RCI methodology used by the survey itself Page 26: Appendix A indicates an appreciation for nuanced evaluation. For a long-term memory benchmark, especially one involving KGs, metrics could include KG quality measures (precision, recall of facts, consistency), efficiency of operations, and the ability to support complex reasoning over time, aligning with the user’s reasoning LLM. The paper also lists various metrics used in existing datasets like BLEU, ROUGE, EM, F1, MAP, and PPL Page 27: Table 2, which can be considered.
- Relevance to Hierarchical KG: The discussion on “Contextual Structured Memory” (like KGs) Page 3: Memory Taxonomy and operations like “graph-based” indexing (e.g., HippoRAG Page 5: Memory Indexing) and multi-hop graph traversal Page 7: Memory Retrieval directly informs how a benchmark could be designed to test the specific strengths and weaknesses of a hierarchical KG architecture for long-term memory. The benchmark could include tasks that specifically stress the hierarchical nature and dynamic updating capabilities of such a KG.
- Future Directions for Benchmarking: The paper’s “Open Challenges and Future Directions” section Page 13: Open Challenges and Future Directions highlights areas like “Spatio-temporal Memory,” “Lifelong Learning,” and “Brain-Inspired Memory Models.” These could inspire novel tasks or evaluation dimensions for a forward-looking long-term memory benchmark, ensuring it assesses cutting-edge capabilities relevant to persistent AI memory.