Paper PDF: Wu et al. - 2025 - LongMemEval Benchmarking Chat Assistants on Long-Term Interactive Memory.pdf (ICLR2025)
Paper Bib: Wu, Di, et al. LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory. 2, arXiv:2410.10813, arXiv, 4 Mar. 2025. arXiv.org, https://doi.org/10.48550/arXiv.2410.10813.
This is the benchmark mentioned by survey: Reading - (Survey) Rethinking Memory in AI
The dataset has these features:
question_type: ‘single-session-user’, ‘multi-session’, ‘single-session-preference’, ‘temporal-reasoning’, ‘knowledge-update’, ‘single-session-assistant’question_id,question: the question for evaluateanswer: expected answerquestion_date: in format like 2023/05/30 (Tue) 23:40haystack_dates,haystack_session_ids,haystack_sessions,answer_session_ids: The history message/dialogues, extensively large.
Goal and Scope of the Benchmark
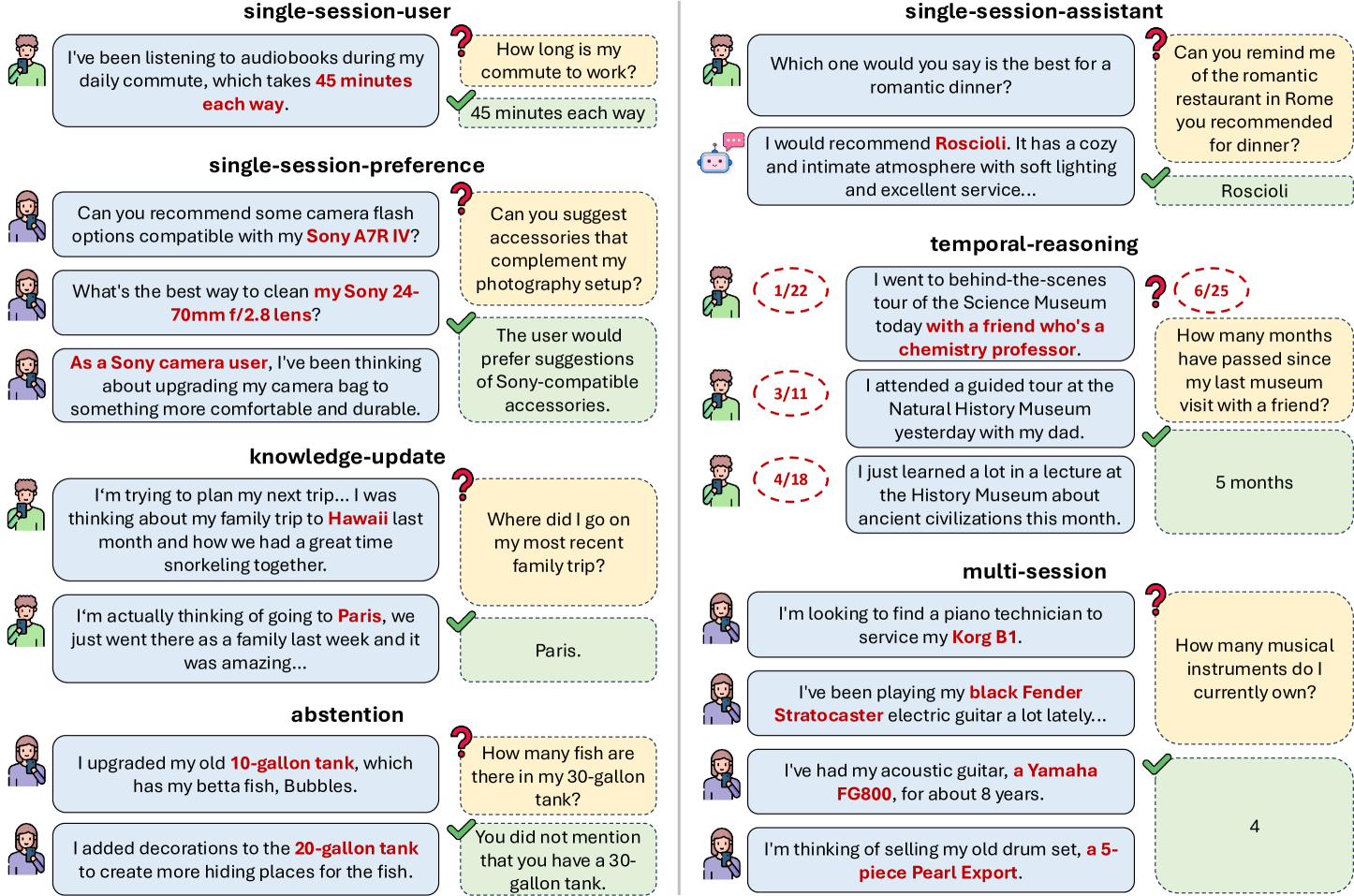
LONGMEMEVAL is a comprehensive benchmark designed to evaluate the long-term memory capabilities of Large Language Model (LLM)-driven chat assistants. The authors argue that this benchmark is needed because existing benchmarks do not accurately reflect user-AI interactions (often focusing on human-human conversations or omitting task-oriented dialogues) and have limited coverage of memory abilities required in dynamic long-term interactions, such as recalling assistant-side information or reasoning with updated user information over extended, configurable history lengths Page 1: Introduction, Page 2: Introduction.
Benchmark Description and Key Components
- Dataset: LONGMEMEVAL consists of 500 meticulously curated questions. Each question requires recalling information embedded within one or more task-oriented dialogues between a user and an assistant. The chat histories are designed to be coherent and length-configurable, inspired by the “needle-in-a-haystack” test Page 2: Introduction. Two standard settings are provided: LONGMEMEVALS (~115k tokens per problem) and LONGMEMEVALM (500 sessions, ~1.5M tokens) Page 2: Introduction.
- Evaluation Tasks (Core Abilities): The benchmark evaluates five core long-term memory abilities Page 4: LONGMEMEVAL: BENCHMARK CURATION:
- Information Extraction (IE): Recalling specific user or assistant-mentioned details.
- Multi-Session Reasoning (MR): Synthesizing information across multiple sessions.
- Knowledge Updates (KU): Recognizing and adapting to changes in user information over time.
- Temporal Reasoning (TR): Awareness of temporal aspects, including explicit time mentions and metadata.
- Abstention (ABS): Identifying and correctly responding to questions about unknown information. These are tested via seven question types: single-session-user, single-session-assistant, single-session-preference, multi-session, knowledge-update, temporal-reasoning, and false-premise questions for abstention Page 4: LONGMEMEVAL: BENCHMARK CURATION.
- Metrics:
- Question Answering: LLM-based evaluation using GPT-4o to assess response quality against a correct answer or rubric, achieving >97% agreement with human experts Page 5: EVALUATION METRIC, Page 6: EVALUATION METRIC.
- Memory Recall: For systems that expose retrieval results, Recall@k and NDCG@k are used, leveraging human-annotated answer locations Page 6: Memory Recall.
- Baseline Results: Pilot studies showed significant performance drops (30-60%) for existing long-context LLMs on LONGMEMEVALS. Commercial systems like ChatGPT and Coze also showed substantial accuracy degradation (37-64% drop for GPT-4o versions) compared to offline reading, even on shorter histories Page 2: Introduction, Page 6: LONGMEMEVAL REPRESENTS A SIGNIFICANT CHALLENGE.
- Novel Evaluation Methodologies: The benchmark features a “needle-in-a-haystack” style setup with dynamically compiled, length-configurable chat histories. It also introduces a structured approach to evaluating a broader set of core memory abilities than previous benchmarks Page 2: Introduction, Page 3: Table 1. The use of an LLM for judging QA responses with high human agreement is also a key part of the methodology Page 5: EVALUATION METRIC, Page 6: EVALUATION METRIC.
Benchmark Creation and Validation Methodology
The benchmark creation involved several steps:
- Attribute Ontology Definition: An ontology of 164 user attributes across five categories (lifestyle, belongings, etc.) was defined Page 4: Question Curation, Page 17: Attribute Ontology.
- Background and Question Generation: Llama 3 70B Instruct was used to generate attribute-focused user background paragraphs. Seed (question, answer) pairs were proposed by an LLM and then manually filtered and rewritten by human experts for difficulty and diversity. Answers were decomposed into evidence statements with optional timestamps Page 4: Question Curation, Page 5: Question Construction.
- Evidence Session Construction: Each evidence statement was embedded into a task-oriented evidence session created via LLM self-chatting (Llama 3 70B Instruct), designed to convey evidence indirectly. These sessions were then manually screened and edited for quality, evidence inclusion, natural language, and correct positioning of evidence Page 5: Evidence Session Construction.
- History Compilation: For each question, a coherent user-AI chat history is compiled by sampling unrelated user-AI chat sessions (from ShareGPT, UltraChat, and other non-conflicting simulated chats) and randomly inserting the evidence sessions, with plausible timestamps assigned Page 5: History Compilation. To validate the benchmark’s difficulty and utility, pilot studies were conducted on commercial chat assistants (ChatGPT, Coze) and state-of-the-art long-context LLMs, demonstrating significant performance degradation on LONGMEMEVAL tasks Page 6: LONGMEMEVAL REPRESENTS A SIGNIFICANT CHALLENGE. The LLM-based evaluation metric was validated against human expert judgments, showing high agreement Page 6: EVALUATION METRIC.
Critical Analysis
- Limitations of the Benchmark:
- The paper acknowledges that the LLM-based judge for QA, while having high agreement with humans, still showed slight deviations for “single-session-preference” and “abstention” problems due to their open-ended nature Page 20: A.4 EVALUATION METRIC BUILDING.
- The evaluation of commercial systems was done on shorter histories than the full LONGMEMEVALS due to interface limitations, and some question types were skipped Page 6: Commercial systems, Page 21: HUMAN STUDY ON COMMERCIAL MEMORY CHATBOTS.
- While “freely scalable,” the paper primarily focuses on two specific lengths (S and M). The impact of vastly different scales or content types within the “haystack” could be further explored.
- Adequacy for Complexities: The benchmark makes a strong effort to cover complexities by including diverse memory abilities, task-oriented dialogues, assistant-side information, knowledge updates, and temporal reasoning Page 4: LONGMEMEVAL: BENCHMARK CURATION. The configurable length and the “needle-in-a-haystack” approach add to its challenging nature.
- Potential “Gaming”: The paper does not explicitly discuss potential “gaming” of the benchmark. However, the diversity of tasks and the indirect embedding of evidence aim to make superficial solutions less effective. The reliance on LLM-based evaluation might be a point to monitor for unforeseen biases or exploitable patterns as models evolve.
- Ethical Considerations: The authors discuss ethical considerations, including the use of publicly licensed datasets (ShareGPT, UltraChat) for history construction and the rigorous human screening to avoid PII or offensive content in newly created data Page 11: ETHICS STATEMENT. They also highlight potential societal impacts like information leakage and the need for memory deletion and moderation mechanisms in memory-augmented systems Page 11: ETHICS STATEMENT.
Relatives and Insights (Focused on Long-Term Memory Benchmark)
- Relevance of Core Abilities for KG-based Memory: The five core abilities tested by LONGMEMEVAL (Information Extraction, Multi-Session Reasoning, Temporal Reasoning, Knowledge Updates, Abstention) Page 4: LONGMEMEVAL: BENCHMARK CURATION are directly applicable to evaluating a KG-based memory system.
- Information Extraction: Essential for populating the KG with facts from interactions.
- Multi-Session Reasoning: KGs excel at connecting information; this ability tests reasoning over facts accumulated across sessions and potentially linked in the KG.
- Temporal Reasoning: A dynamic KG should handle time-sensitive information; this aspect of LONGMEMEVAL provides a template for testing temporal queries and reasoning over evolving states in the KG.
- Knowledge Updates: Crucial for dynamic KGs. Tasks evaluating KU can test how well the KG can add, modify, or deprecate nodes and relationships as new information arrives.
- Abstention: Important for any robust AI; for KGs, this means not hallucinating facts not present or inferable from the graph.
- Adaptable Dataset Creation Methodology: The “needle-in-a-haystack” approach and the pipeline for creating length-configurable chat histories embedding specific evidence Page 2: Introduction, Page 5: History Compilation can be adapted. Instead of unstructured chat histories, the “haystack” could be a series of updates or interactions that dynamically build/modify the KG. The “needles” would be questions requiring retrieval and reasoning over this evolving KG.
- The attribute ontology and LLM-based generation of background/evidence Page 4: Question Curation, Page 5: Evidence Session Construction can inspire systematic generation of test cases relevant to user modeling and event tracking within the KG.
- Metrics for KG Evaluation: While LONGMEMEVAL uses QA accuracy and memory recall (Recall@k, NDCG@k) Page 5: EVALUATION METRIC, Page 6: Memory Recall, a KG-focused benchmark could extend these. For instance:
- KG State Evaluation: Metrics assessing the KG’s accuracy (precision/recall of facts, relations) after a series of interactions.
- Query Efficiency: Time taken to answer queries that require traversing the KG.
- Dynamic Update Performance: How quickly and accurately the KG reflects new information or updates.
- The LLM-based QA evaluation from LONGMEMEVAL Page 5: EVALUATION METRIC, Page 6: EVALUATION METRIC could be adapted to assess the quality of answers generated by the reasoning LLM using the KG.
- Challenging Existing Systems: LONGMEMEVAL’s finding that even SOTA LLMs struggle with long-term memory tasks Page 6: LONGMEMEVAL REPRESENTS A SIGNIFICANT CHALLENGE underscores the need for robust memory solutions like the proposed KG. A benchmark inspired by LONGMEMEVAL could effectively showcase the advantages of such a structured, dynamic memory system over simpler baselines.
- Framework for Memory Design: The paper’s unified framework for long-term memory design (indexing, retrieval, reading) and the identified control points (value, key, query, reading strategy) Page 7: A UNIFIED VIEW OF LONG-TERM MEMORY ASSISTANTS provide a conceptual lens. A benchmark could be structured to probe performance at each of these stages within the context of a KG. For example:
- Value/Key in KG: How are interaction snippets or derived facts represented as nodes/edges (value) and indexed (key) in the KG?
- Query for KG: How are user queries translated into KG queries (e.g., SPARQL, graph traversals)?
- Reading from KG: How does the reasoning LLM utilize the retrieved KG subgraphs?
- Insights from Optimizations: The optimizations proposed (session/round decomposition, fact-augmented key expansion, time-aware query expansion, Chain-of-Note reading) Page 8: Value: DECOMPOSITION IMPROVES RAG PERFORMANCE, Page 9: KEY: MULTI-KEY INDEXING IMPROVES RETRIEVAL AND RAG, QUERY: TIME-AWARE QUERY EXPANSION IMPROVES TEMPORAL REASONING, Page 10: IMPROVING READING WITH CHAIN-OF-NOTE AND STRUCTURED FORMAT offer ideas for how a KG-based system might be designed and, consequently, what aspects a benchmark should test. For instance, “fact-augmented key expansion” Page 9: KEY: MULTI-KEY INDEXING IMPROVES RETRIEVAL AND RAG is directly relevant to how nodes in a KG might be indexed for better retrieval.